If you’ve used YouTube playlists before, then you’re sure to have seen the dreaded message: “One or more videos have been removed from the playlist.” If you have hundreds of items in your playlists, then you’re stuck wondering which item went missing?
I keep hundreds of songs in playlists on YouTube, and I’ve been dealing with this problem for too long. My first ‘solution’ was to just save the whole playlist page once in a while for reference, then look back through it to check for which videos went missing. But that was really tedious, and I didn’t do a great job of tracking the playlist changes myself. So I went to work on a better solution.
The idea is simple:
- Run a script that automatically downloads a list of video information for a playlist
- Save that information to a file on the computer.
- Each time the script is run, check for differences between the previous playlist and the current playlist.
- Track the new changes (removed item, added item or retitled item) and save the new information.
My original script was written in PowerShell (You can find the script in the same repository at /powershell). It was a decent first attempt, but PowerShell can only be run on Windows machines, and I wanted something that could be run on Windows, Linux or MacOS. I also felt there were several areas for improvement with the original PowerShell version. So I rewrote my YouTube Tracker in Python, and added a few extra features as well.
If you’re interested in setting up and using this script yourself, you can find it on GitLab at https://gitlab.com/midfords/playlist-tracker. Instructions for installing and configuring the script can be found in the project’s readme file.
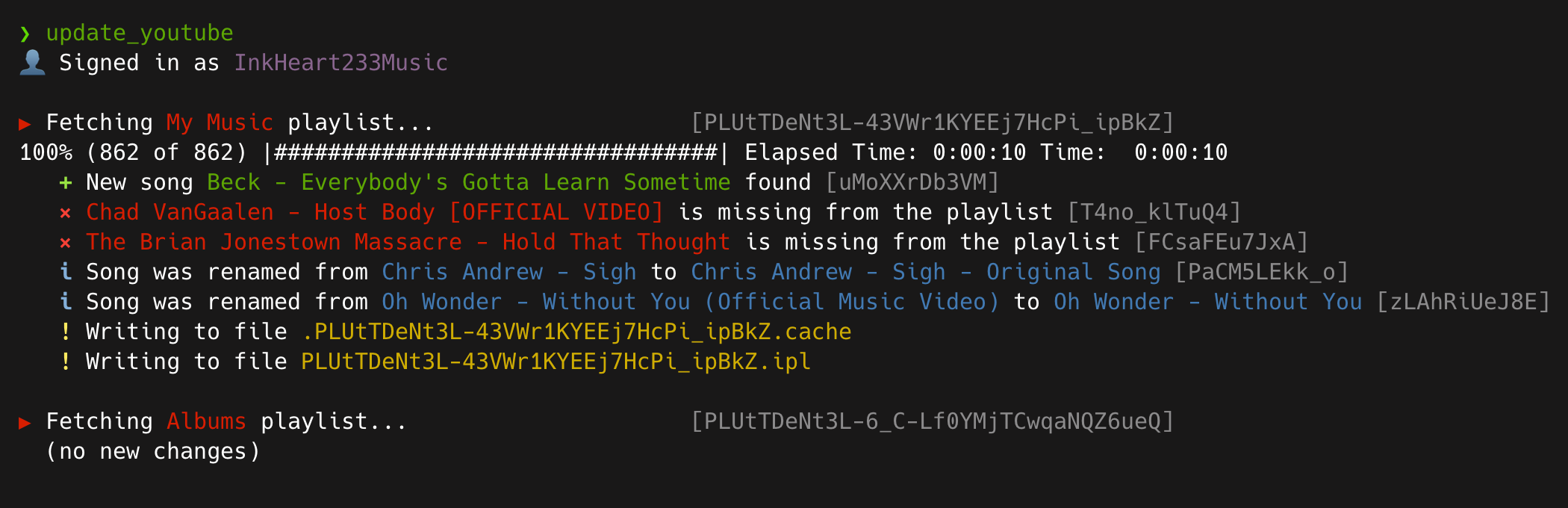
Screenshot of YouTube Tracker.
The Diff Functions
There are three primary functions that drive this program. They detect the added, missing and renamed items between the new and old sets of data.
There were a few constraints that needed consideration when writing these functions. Firstly, the order of the items in the two sets is not guaranteed, and the reordering of lines in a playlist should not trigger false positives. Secondly, it would be difficult to tell which items were renamed simply by comparing the two titles directly. This is because YouTube will sometimes retitle a video to a generic label such as ‘Deleted Video’ or ‘Private Video’. Based on this alone, it would be impossible to tell which of the playlist items have been retitled. Running a basic diff algorithm over the two sets would not be able to detect changes.
Luckily there is a property that is guaranteed to never change, the video id. Using the video id, we could compare items directly from one set to another, even if the items have changed drastically. This simplifies the problem to a comparison of two sets, the set of old ids and the set of new ids.
New set:
{ video_id_0, video_id_1, video_id_2, video_id_3 }
Old set:
{ video_id_0, video_id_1, video_id_2 }
We can find a set of the missing items or added items by subtracting the sets like so:
added_set = new_items – old_items
missing_set = old_items – new_items
Or, by using Python list comprehensions, we can organize the results into lists:
added_items = [ (id, title) for id, title in new_items if id not in old_items ]
missing_items = [ (id, title) for id, title in old_items if id not in new_items ]
renamed_items = [ (id, title) for id, title in old_items if id in new_items and title != new_items[id] ]
The .ipl File
The information downloaded from YouTube needs to be stored somewhere on the user’s computer. This is used as a reference point to compare against when looking for changes. For a project this small, I didn’t bother with a proper database, and just saved the information to a csv-like file instead. I defined my own file extension ‘ipl’ for internet playlists.
Under the hood, an ipl file is just a csv file with a few additional constraints. The first row is reserved for the header, which contains some metadata about the playlist. Each row thereafter is used to store the video information.
The header is formatted as: ipl_tag, ipl_version, source, item_count, playlist_id, playlist_name.
Each row is formatted as: code, video_id, video_title. The code is set to ‘!’ meaning missing, or ” meaning present.
Here’s an example ipl file:
#IPL,1.1,YOUTUBE,13,PLUtTDeNt3L-43VWr1KYEEj7HcPi_ipBkZ,My Music
,dQw4w9WgXcQ,Rick Astley – Never Gonna Give You Up (Video)
!,n4FEdN9uccE,My pillow is the Threshold / Silver Jews
,W2lkB64QaE8,Rosalyn – LoverFriend
Google Oauth2
At first, my script only worked with public playlists. To access public YouTube information all you need is an API key from Google. Accessing private playlists is trickier because you actually have to log in using your Google account and set up your script as a registered affiliate.
Thankfully, you can skip the verification part as long as you don’t mind a giant warning screen every time you try to log in to your account. This is fine, since the user will only log in once upon first use. And somehow I don’t see Google officially verifying my hacky python script.
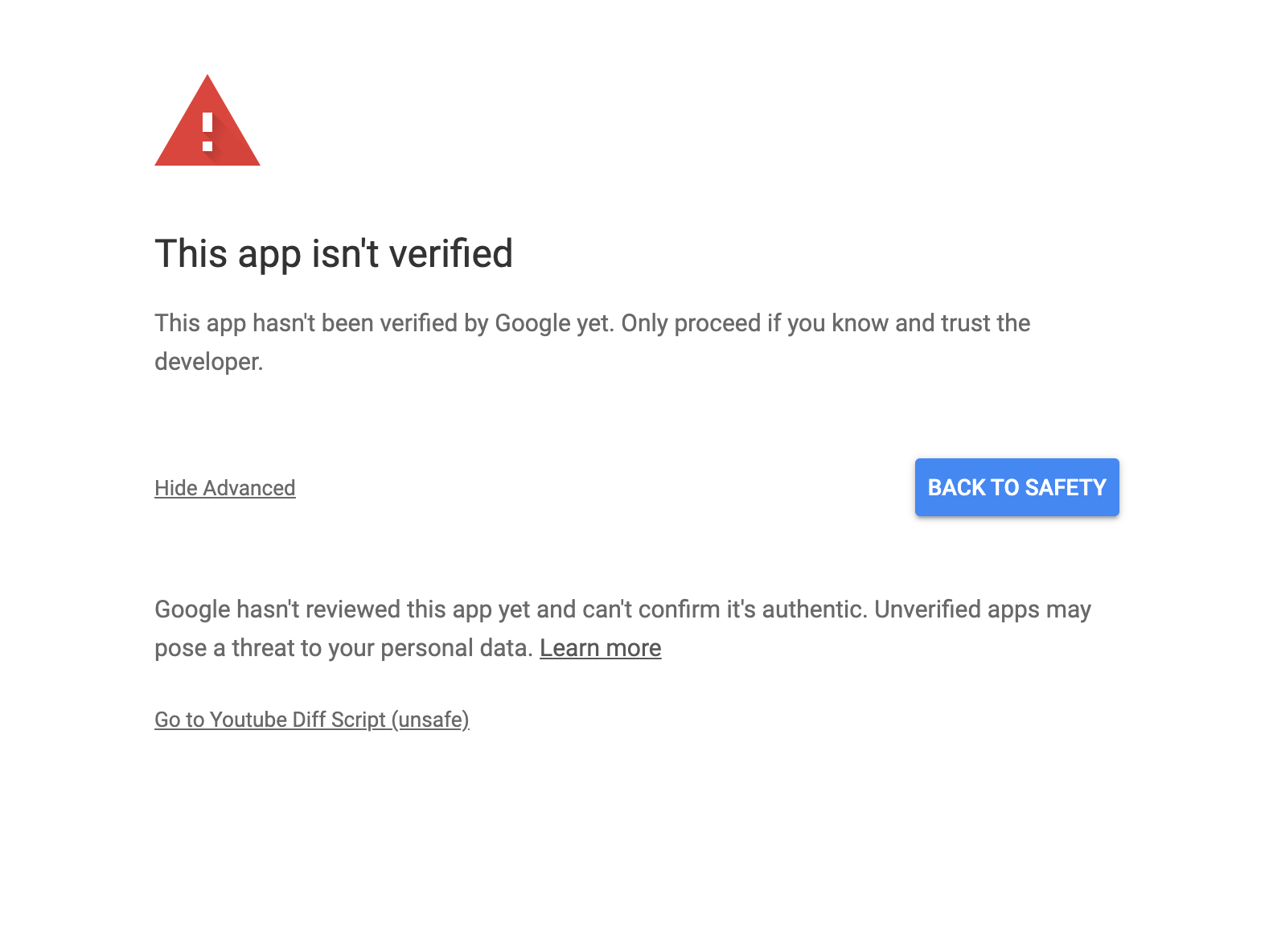
Screenshot of unverified app warning.
I found Oauth2 difficult to get working and, although Google offers a Python Oauth2 library for python, I ended up writing my own version. I wrote the following function to check for authentication credentials and refresh the token. The script will start a new authentication flow if no credentials are found, the token has expired or the reauth flag was passed.
def auth():
scope = [“https://www.googleapis.com/auth/youtube.readonly”]
storage_path = os.path.join(module_dir, ‘auth/credentials.storage’)
storage = Storage(storage_path)
credentials = storage.get()
credentials.refresh(httplib2.Http())
credentials_empty = credentials is None
credentials_expired = \
credentials.__dict__[“token_expiry”] < datetime.datetime.now() or \
credentials.invalid
if credentials_empty or credentials_expired or reauth_flag_passed:
flow = flow_from_clientsecrets(client_secret, scope=scope)
flags = argparser.parse_args(args=[])
credentials = run_flow(flow, storage, flags=flags)
return credentials.__dict__[“access_token”]
Conclusion
This wasn’t a particularly large project, and the code isn’t overly complex. Although the Oauth2 part was challenging to get working, overall, I’m happy with how this project turned out. It’s a simple idea, executed well.
Cheers! 🍻